
I’ll be taking statistical learning class next semester. So I just wanted to get a head start on some of the algorithms. I’m currently enrolled in an online class called Predictive Analytics offered through coursera and this is pretty much my “partial” answers to one of the assignments. I hope to use this code as a template for future assignments. The code uses decision tree, random forest and support vector machine on flow cytometer data to compare accuracy of three models.
A flow cytometer delivers a flow of particles through capilliary. By shining lasers of different wavelengths and measuring the absorption and refraction patterns, you can determine how large the particle is and some information about its color and other properties, allowing you to detect it.
While there are a number of challenging analytics tasks associated with this data, a central task is classification of particles. Based on the optical measurements of the particle, it can be identified as one of several populations.

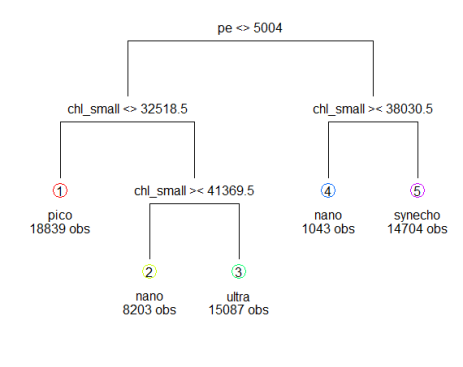
Looks like CRYPTO is missing using Decision Tree! Let’s look at the accuracy of Decision Tree, Random Forest and SVM .

The accuracy using DT, RF and SVM were .854, .923, and .921 respectively. Also, the most important variables in the data set, as suggested by Gini impurity measure were, pe and chl_small. The higher the index, the more important is the variable! Upon deleting one of the observations the accuracy of the svm model went up by 0.05. Here’s the confusion matrix from three models.

All the three models suggest Ultra being misclassified in higher proportion as Pico and Nano. Also, Synecho is misclassified as pico.


